















Tech-Guide
To Harness Generative AI, You Must Learn About “Training” & “Inference”
Unless you’ve been living under a rock, you must be familiar with the “magic” of generative AI: how chatbots like ChatGPT can compose anything from love letters to sonnets, and how text-to-image models like Stable Diffusion can render art based on text prompts. The truth is, generative AI is not only easy to make sense of, but also a cinch to work with. In our latest Tech Guide, we dissect the “training” and “inference” processes behind generative AI, and we recommend total solutions from GIGABYTE Technology that’ll enable you to harness its full potential.

Generative AI is not actually a robot holding a paintbrush, of course. But this evocative image represents how endearing, capable, and inspiring the future of AI can be.
Training: How It Works, Which Tools to Use, and How GIGABYTE Can Help
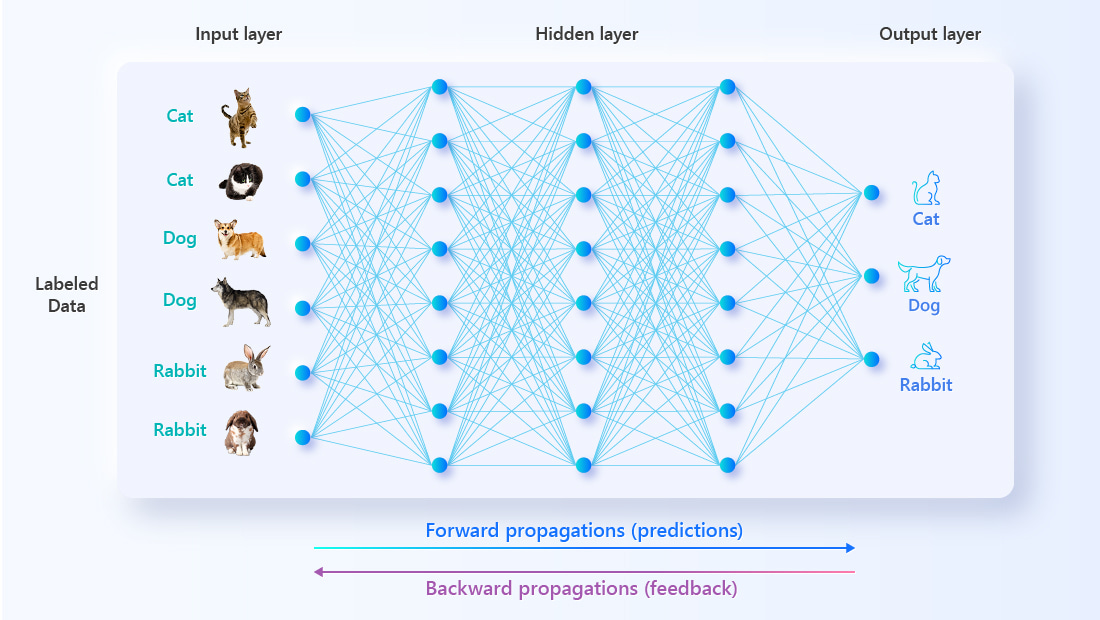
Typically, during the AI training process, a sea of labeled data is poured into the algorithm for it to “study”. The AI makes guesses and then checks the answers to improve its accuracy. Over time, the AI becomes so good at guessing that it’ll always make the correct guess; in other words, it’s “learned” the information that you wanted it to work with.

GIGABYTE’s G593-SD0 and G593-ZD2 integrate the most advanced 4th Generation Intel® Xeon® and AMD EPYC™ 9004 CPUs, respectively, with NVIDIA’s HGX™ H100 computing module inside a 5U chassis. This is one of the most powerful AI computing platforms on the planet, and it can be the linchpin in your AI training setup.
Inference: How It Works, Which Tools to Use, and How GIGABYTE Can Help
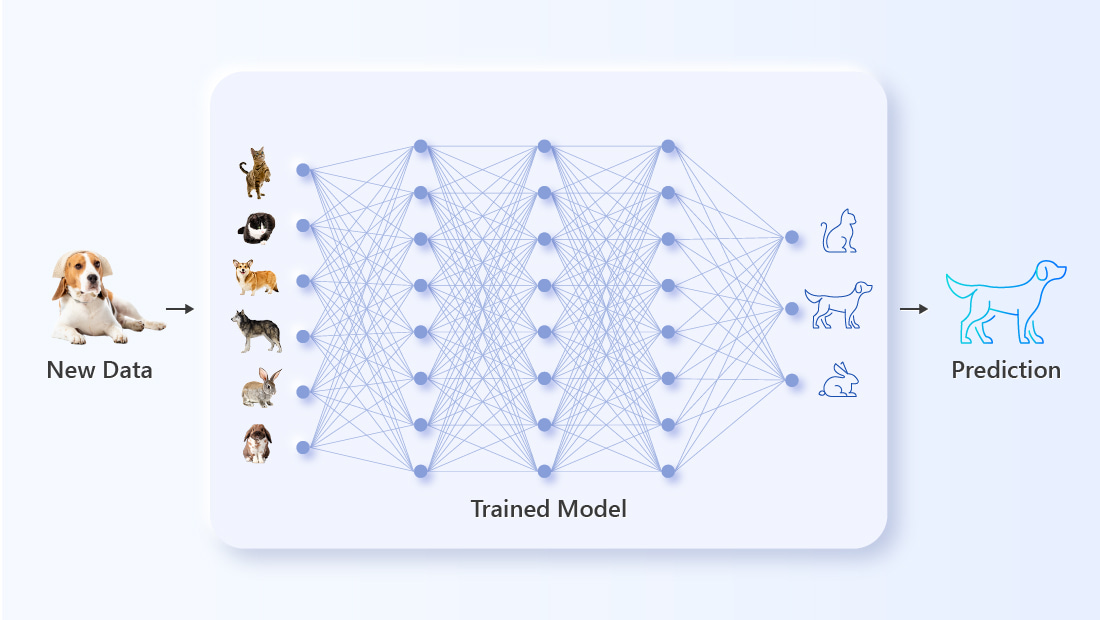
During the AI inference process, unfamiliar, unlabeled input is fed into the pre-trained model. The AI compares the parameters of the new data to its training and tries to make the correct prediction. Successes and failures during the inference phase are used in the next training session to further improve the AI.

GIGABYTE’s G293-Z43 provides an industry-leading ultra-high density of sixteen AMD Alveo™ V70 Inference Accelerator Cards in a compact 2U chassis. This setup offers surpassing performance and energy efficiency, as well as lower latency. Such a dense configuration is made possible by GIGABYTE’s proprietary server cooling technology.
Get the inside scoop on the latest tech trends, subscribe today!
Get Updates
# Artificial Intelligence (AI)
# Machine learning (ML)
# Natural Language Processing (NLP)
# AI Training
# AI Inference
# Deep Learning (DL)
# Generative AI (GenAI)
# Supercomputing
# Computer Vision
# Cloud Computing
# Data Center
Get the inside scoop on the latest tech trends, subscribe today!
Get Updates