















Tech-Guide
Cluster Computing: An Advanced Form of Distributed Computing
Cluster computing is a form of distributed computing that is similar to parallel or grid computing, but categorized in a class of its own because of its many advantages, such as high availability, load balancing, and HPC. GIGABYTE Technology, an industry leader in high-performance servers, presents this tech guide to help you learn about cluster computing. We also recommend GIGABYTE servers that can help you benefit from cluster computing.

Strength in Numbers: Why More is Better for Supercomputers
Comparison between Cluster Computing and Parallel Computing
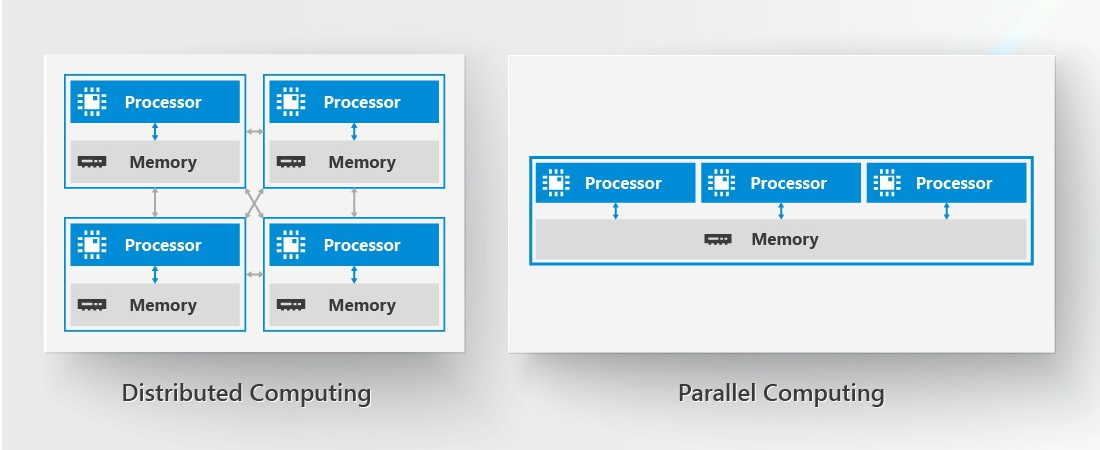
While the two terms are sometimes used interchangeably, some differentiate between distributed computing and parallel computing by the amount of resources that are shared between the processors. A greater or lesser amount of shared resources, such as the computer memory, may be more suitable for some specific tasks.
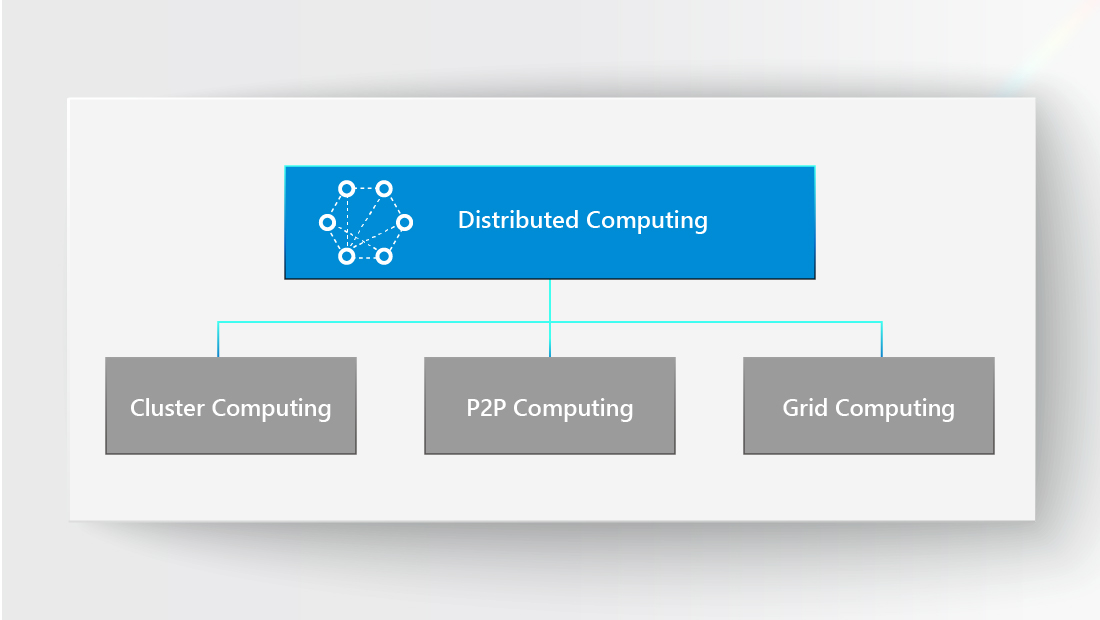
Distributed computing can be seen as the umbrella term that encompasses other forms of parallelism, including cluster computing, peer-to-peer computing, and grid computing. All of them offer varying levels of availability and reliability. You should select the method that best matches the computing task at hand.
PCs and LAN: The Twin Pillars of Cluster Computing
High Availability, Load Balancing, and High Performance
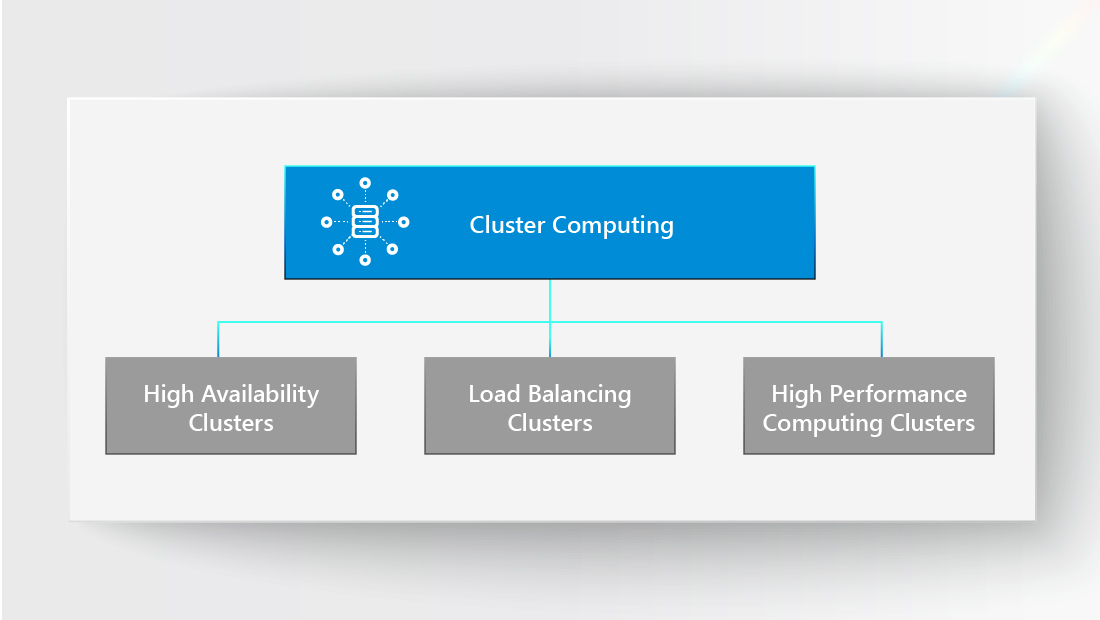
Based on the characteristics of cluster computing systems, they can be categorized as High Availability Clusters, Load Balancing Clusters, or High Performance Computing Clusters. Which type you choose depends greatly on the workload you wish to handle.
● High Availability Clusters
● Load Balancing Clusters
● High Performance Computing Clusters
GIGABYTE Servers Recommended for Cluster Computing

GIGABYTE has a full range of server solutions that are highly recommended for cluster computing. H-Series High Density Servers and G-Series GPU Servers are good for control and computing nodes; R-Series Rack Servers are ideal for business-critical workloads; S-Series Storage Servers can safeguard your data; W-Series Tower Servers / Workstations can be conveniently installed outside of server racks.
● Control Nodes
● Computing Nodes
● Business-Critical Workloads and Reliable Connectivity
● File-sharing and Storage Nodes
Get the inside scoop on the latest tech trends, subscribe today!
Get Updates
# HPC
# Data Center
# Cloud Computing
# Artificial Intelligence (AI)
# Virtual Machine (VM)
# Supercomputing
Get the inside scoop on the latest tech trends, subscribe today!
Get Updates