















Tech-Guide
What is Big Data, and How Can You Benefit from It?
You may be familiar with the term, “big data”, but how firm is your grasp of the concept? Have you heard of the “5 V’s” of big data? Can you recite the “Three Fundamental Steps” of how to use big data? Most importantly, do you know how to reap the benefits through the use of the right tools? GIGABYTE Technology, an industry leader in high-performance server solutions, is pleased to present our latest Tech Guide. We will walk you through the basics of big data, explain why it boasts unlimited potential, and finally delve into the GIGABYTE products that will help you ride high on the most exciting wave to sweep over the IT sector.

What is Big Data? Use the "5 V's" to Remember!

How is “big data” not like any other data? Remember the “5 V’s”, which stand for volume, variety, velocity, veracity, and value. To the modern IT expert, digital data must exhibit all five of these attributes before it can be considered “big data”.
Why is Big Data? The Unique Treasure Trove of Our Time
How is Big Data? The Three Fundamental Steps
The Organization of Big Data
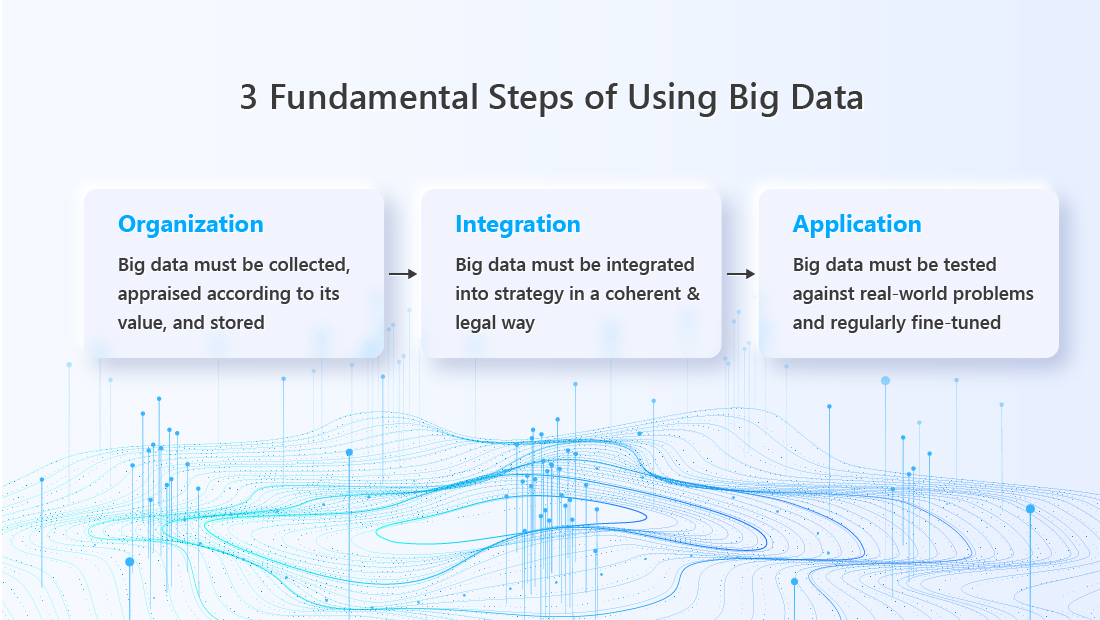
The three fundamental steps of using big data can be remembered as “organization”, “integration”, and “application”. Big data that is valuable must be organized and stored; insight gleaned from it must be legally and coherently integrated into your business strategy (or public policy, etc.) Last but not least, the big data-infused strategy must be able to stand the test of real-life applications, or it must be fine-tuned until it does.
The Integration of Big Data
The Application of Big Data

Big data is already being applied to many aspects of our lives, from something as groundbreaking as artificial intelligence, to something as everyday as the recommender system in your favorite streaming service. The question you need to ask yourself is: what can I do with big data?
Recommended GIGABYTE Server Solutions
Get the inside scoop on the latest tech trends, subscribe today!
Get Updates
# Artificial Intelligence (AI)
# Machine learning (ML)
# HPC
# Cloud Computing
# Data Center
# Supercomputing
# Digital Twin
# Iot
# Natural Language Processing (NLP)
Get the inside scoop on the latest tech trends, subscribe today!
Get Updates